Tiny Bots, Big Brains: Building AI That Grows
Designing Scalable AI Systems Using Microservices and Event-Driven Architecture
Artificial Intelligence (AI) applications are increasingly integral to modern digital platforms. Whether powering recommendation engines, chatbots, fraud detection, or image recognition, scalability, modularity, and robustness are critical. This blog explores how Microservices and Event-Driven Architecture (EDA) help design scalable, maintainable, and performant AI systems.
Why Traditional Monoliths Don’t Work for AI at Scale
AI applications often involve multiple components:
- Data ingestion and preprocessing
- Feature engineering
- Model training and evaluation
- Inference/prediction
- Monitoring and feedback loops
Bundling all these into a monolithic architecture can lead to:
- Tight coupling of components
- Scalability bottlenecks
- Difficulty with CI/CD and testing
- Limited agility in updating models or logic
Microservices: Breaking Down the Problem
Microservices architecture allows developers to break down AI workflows into independent, loosely coupled services. Each microservice can be owned, deployed, and scaled independently.
Key AI Microservices
| Service | Responsibility |
|---|---|
| data-ingestion-service | Pulls data from APIs, logs, or real-time streams. |
| feature-store-service | Stores and serves preprocessed features for training/inference. |
| model-serving-service | Hosts trained ML models and handles prediction requests. |
| model-training-service | Retrains models periodically or on demand. |
| monitoring-service | Monitors model drift, latency, and prediction quality. |
| orchestrator-service | Coordinates jobs and manages workflow logic. |
Each service communicates via APIs or messaging queues and can be independently deployed using containers (e.g., Docker) and orchestrated with Kubernetes.
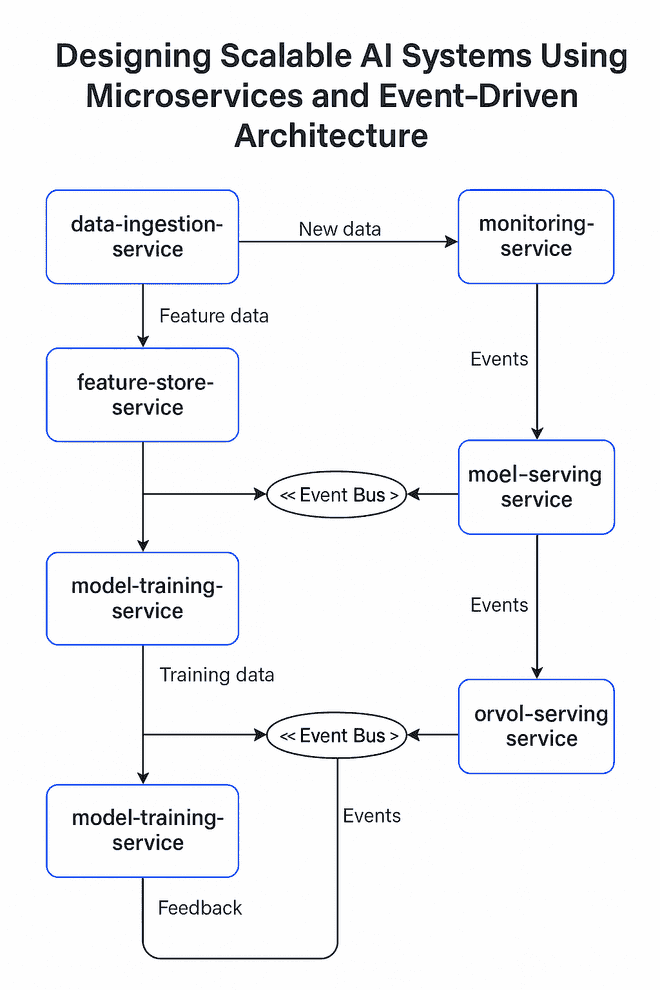
Event-Driven Architecture: Enabling Asynchronous Workflows
In AI systems, events such as “new data uploaded,” “model training completed,” or “anomaly detected” are natural triggers. Event-Driven Architecture (EDA) complements microservices by enabling asynchronous, loosely coupled communication.
Common Event Buses & Brokers
- Apache Kafka: High-throughput distributed messaging
- AWS SNS/SQS: Managed pub-sub and queueing
- RabbitMQ: Lightweight AMQP-based messaging
Sample Event Flow
[New Data Ingested] --> [data-preprocessing-service]
↓
↓ (emits event)
↓
[Event Bus: "features-ready"]
↓
↓
[model-serving-service consumes event]
↓
↓
[Updated real-time prediction available]This model ensures non-blocking communication and scalability, especially in real-time streaming or batch pipelines.
Scalability Benefits
| Dimension | How It's Achieved |
|---|---|
| Compute Scaling | Independent autoscaling of CPU/GPU-bound services |
| Elasticity | Event queues buffer bursts in demand |
| Data Parallelism | Batch processing can be parallelized across services |
| Model Versioning | Models can be updated without affecting upstream/downstream services |
| Fault Isolation | Failure in one service (e.g., retraining) doesn't bring down the entire system |
Observability & Monitoring
With services operating asynchronously, visibility becomes essential.
Observability Tools
- Prometheus + Grafana for metrics
- OpenTelemetry for distributed tracing
- Elasticsearch + Kibana for logs
- Sentry or PagerDuty for alerts
Instrument each service to emit logs, traces, and metrics tied to event lifecycle stages.
Best Practices
- Use a Feature Store: Centralize feature logic across training and inference.
- Ensure Idempotency: Make services resilient to duplicate events.
- Support Schema Evolution: Use schema registries (like Confluent's) to version event data.
- Secure the Event Bus: Use access control, encryption, and audit logging.
- Implement Circuit Breakers & Retries: Handle service failures gracefully.
Real-World Example
Imagine an AI system for real-time fraud detection:
- The transaction-ingestor emits "transaction-received" events to Kafka.
- The feature-enricher subscribes, processes metadata, and emits "features-ready."
- The fraud-detector consumes enriched features, runs the model, and emits "fraud-score-generated."
- The alert-service acts on scores and sends notifications if needed.
This modular and event-driven setup ensures:
- Low-latency inference
- Rapid iteration on models
- Independent scaling based on volume (e.g., more fraud-detector pods during peak hours)
Further Deep Dive
Author:
Rahul Majumdar